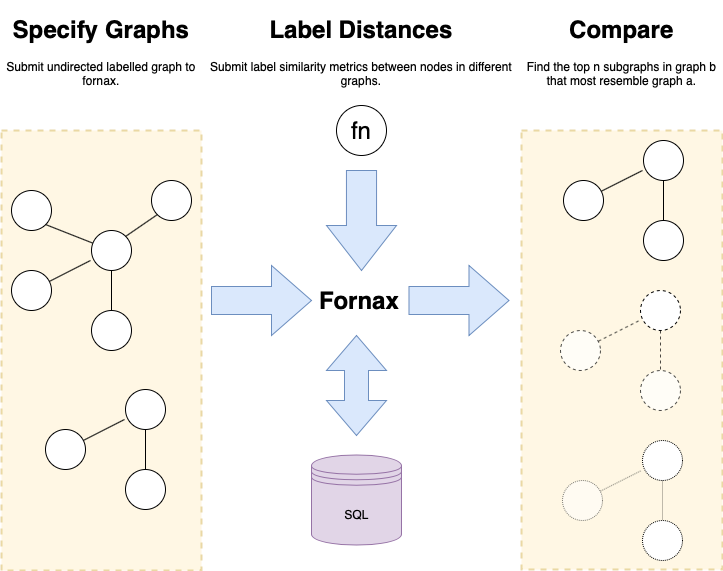
Guide¶
Fornax is an open source library to perform fuzzy subgraph matching between labelled undirected graphs based on NeMa: Fast Graph Search with Label Similarity.
Subgraph Matching¶
A subgraph is any collection of node and edges that form some subset of a graph. For example in the image below the graph on the left is isomorphic to the green nodes in the graph on the right, hence they form a subgraph.
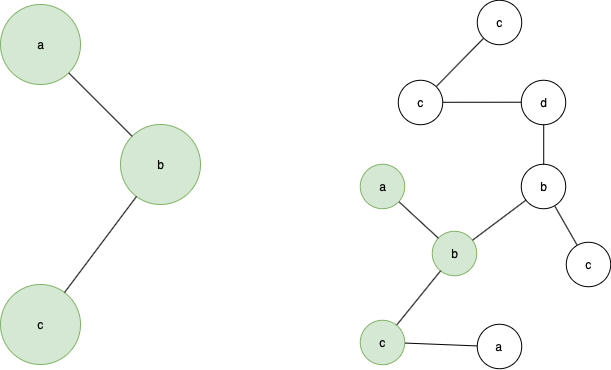
If we refer to the graph on the left as the query graph and the graph on the right as the target graph subgraph matching is the process of finding the query graph in the target graph such that the node labels and edges are strictly the same.
Fornax will kind the n most similar subgraphs in a target graph based on a user specified query graph using a user specified label similarity function.
Fornax will not only find exact subgraph isomorphisms but the n most similar subgraphs even if they are not exact isomorphisms of the query graph. Hence, fornax can be used for fuzzy subgraph matching.
For example, Fornax can be used to find subgraphs where labels are similar, yet different, based on a user specified definition. Additionally neighbours in the query graph may be absent, or are neighbours of neighbours in the target graph.
Example Problems¶
Common fuzzy subgraph matching problems include:
- searching knowledge graphs
- mining social networks
- searching geospation data as a graph
- searching text as a graph
Goals¶
fornax was written with three primary goals in mind
- to demonstrate process and provide ease of use over performance
- to be flexible and accomidate the users notions of similarity
- to scale to large target graphs of millions of nodes and edges
Architecture¶
In order to support large graphs and persist them between python interpreter sessions fornax stores all data in a database.
To facilite ease of use fornax can use sqlite or postgresql as a back end. For more details see the API Introduction.